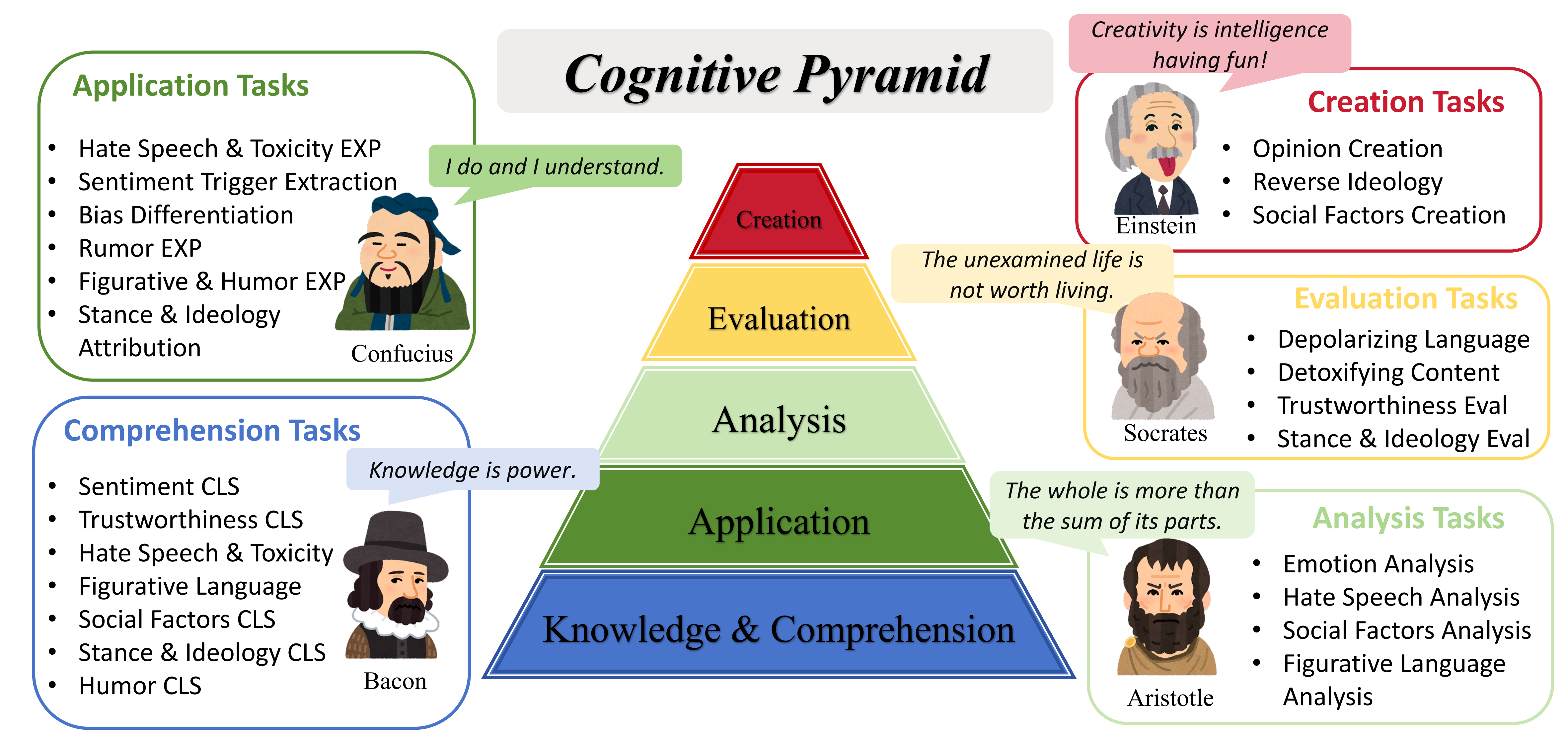
An illustration of Our Social Media Cognitive Framework. We build a cognitive pyramid based on Bloom's Taxonomy, including cognitive levels of Knowledge & Comprehension, Application, Analysis, Evaluation, and Creation. These cognitive abilities are derived from different types of users on social media and represent different levels of demands for information processing.
Background
The growth of social media, characterized by its multimodal nature, has led to the emergence of diverse phenomena and challenges, which calls for an effective approach to uniformly solve automated tasks.
The powerful Large Vision Language Models make it possible to handle a variety of tasks simultaneously, but even with carefully designed prompting methods, the general domain models often fall short in aligning with the unique speaking style and context of social media tasks.
In this paper, we introduce a Large Vision Language Model for Social Media Processing (SoMeLVLM), which is a cognitive framework equipped with five key capabilities including knowledge & comprehension, application, analysis, evaluation, and creation.
Our Contributions
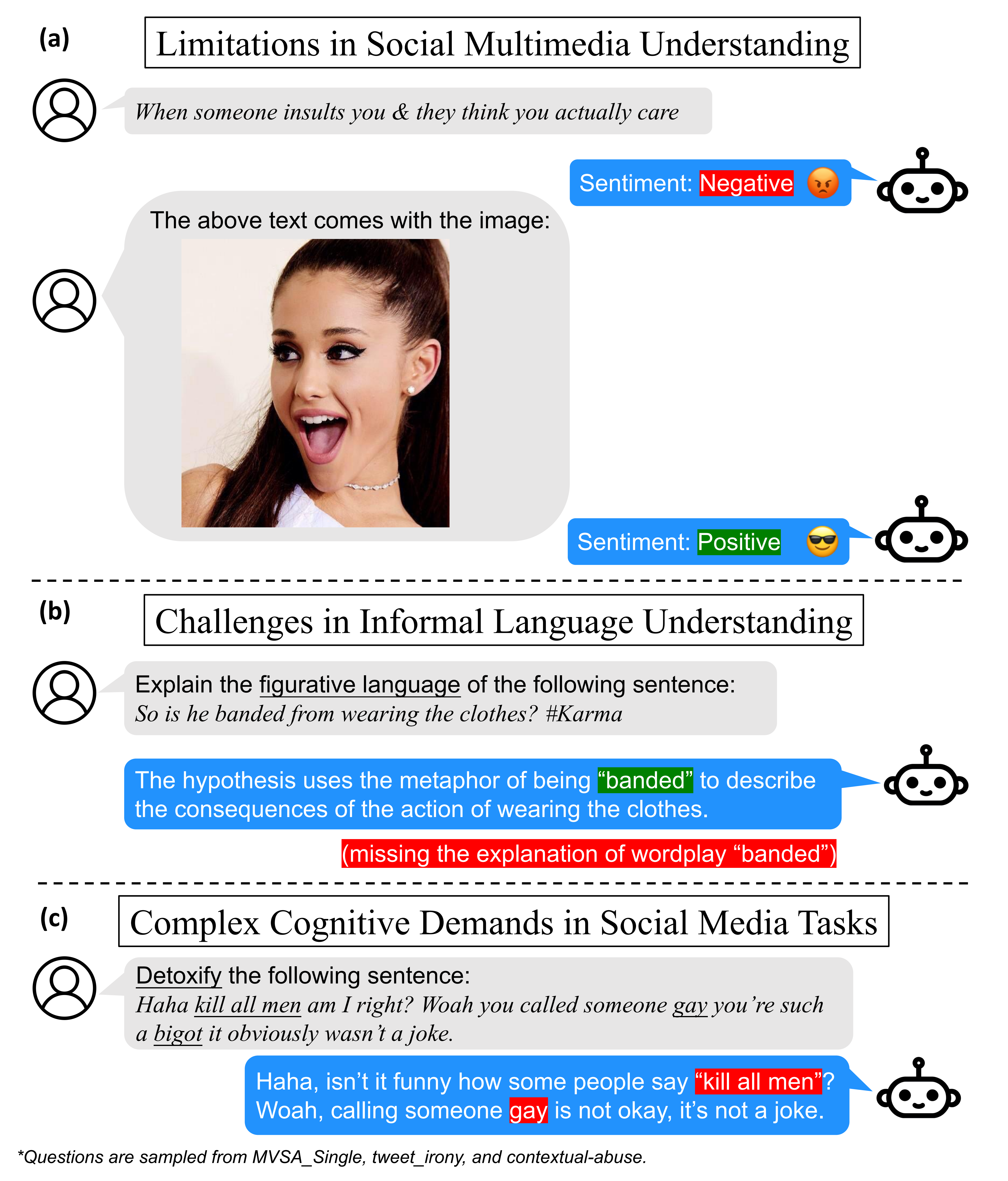
We discover three major challenges faced by general domain models in addressing the nuances of social media: Limitations in social multimedia understanding(Figure (a)), Challenges in informal language understanding(Figure (b)), Unable to Cope with Complex cognitive demands in social media tasks(Figure (c)). Overall, the contributions of our paper are as follows:
- Large Vision Language Model SoMeLVLM: We propose a large vision language model specifically tailored for social media contexts, capable of delivering high-quality text classification and interpretation under zero-shot conditions, fundamentally simplifying the research workflow in computational social science and improving overall reliability.
- Social Media Cognitive Pyramid: We construct a comprehensive social media framework by combining cognitive abilities with traditional social media tasks to support different levels of demands in information processing.
- High-quality Multimodal Dataset: We contribute to a large-scale, high-quality multimodal social media dataset, encompassing both pure text and multimodal formats, with data from both open-source and self-collected sources, formatted into diverse instruction-tuning formats.
Framework Design
We design a cognitive pyramid according to Bloom's Taxonomy, which is a classic teaching theory proposed by Benjamin Bloom in 1956. The pyramid contains five cognitive levels: Knowledge & Comprehension, Application, Analysis, Evaluation, and Creation.
- Knowledge & Comprehension Level: This level means to recall and understand basic facts. The instruction construction of this level consists of various classification tasks within the context of social media.
- Application Level: The Application level means to use the information in new situations. The instruction construction is to make accurate interpretations based on the given ground truth over various social media domains, implying an understanding of the reasons behind the labels.
- Analysis Level: The analysis level requires the model to analyze the label and furnish the corresponding interpretations independently. We aim for the model to offer explanations in the absence of ground truth labels at this level.
- Evaluation Level: At the evaluation level, we pay special attention to the existing prejudices within the data and the abnormal behavior on social media. The construction of the data is divided into two aspects: (1) we undertake detoxification or depolarization for abnormal texts. (2) we instruct the model to explain the underlying reasons for texts or text-image pairs labeled as Misinformation.
- Creation Level: The Creation level means to create reliable content related to social media. We tackle this demand by setting reverse and creation tasks. In the reverse task, we require the model to generate opposing viewpoints based on a specified topic and text. In the create task, the task is formulated as the generation of new hashtags on social media.
Datasets
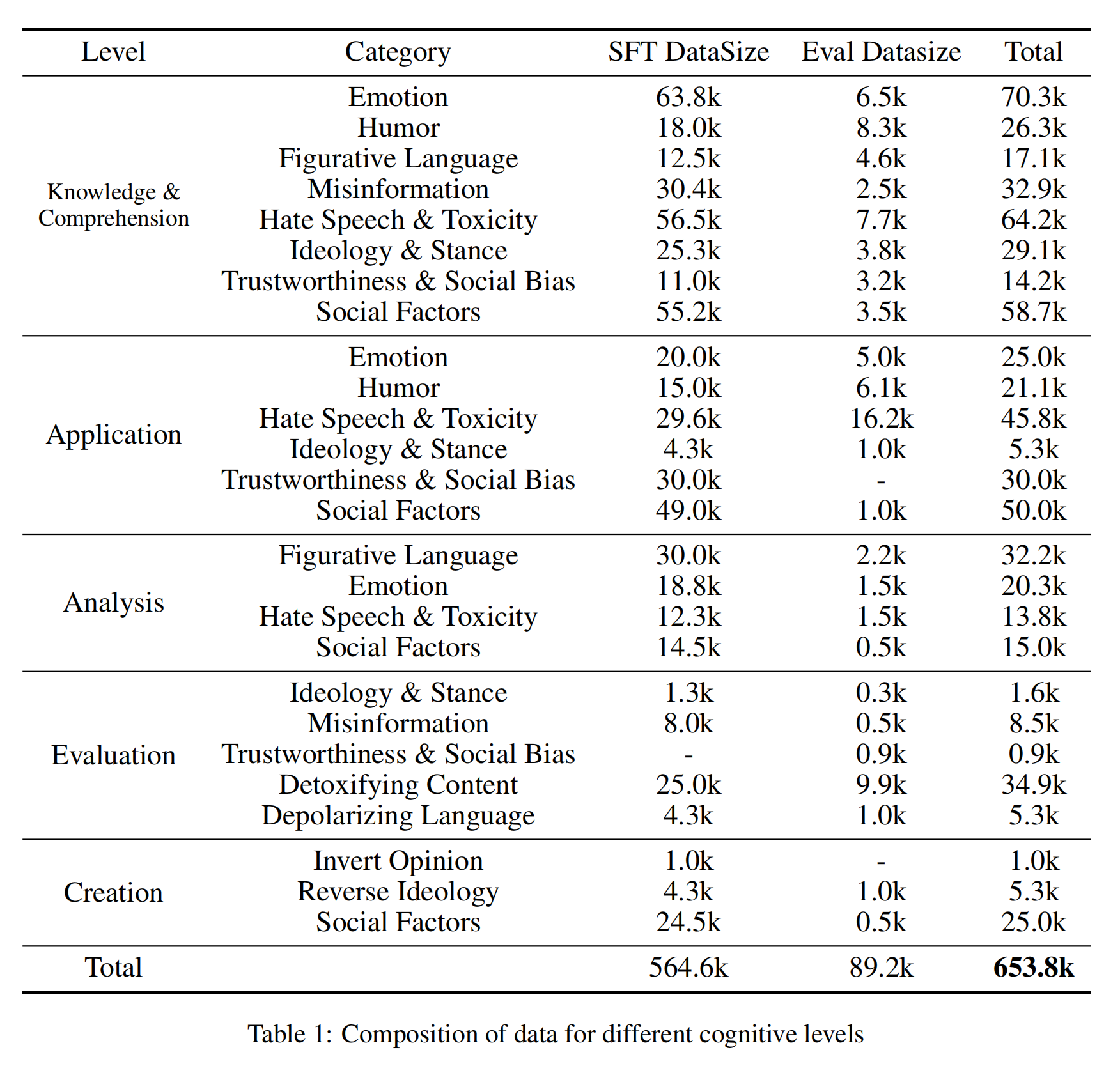
We have develop a 654k social media dataset SoMeData, which consists of five cognitive modules and various CSS task categories.
Experiment Results
We conduct both classification task and generation task on both plain text domain and multimodal domain. Specifically, for tasks containing images, we choose Blip2, InstructBlip (both Vicuna-based and FlanT5xl-based), Llava, and Minigpt4 as our baseline models. And for tasks involving plain text, we select Llama-2-7b-chat-hf, Vicuna-7b-v1.1, and ChatGLM2-6B as our baseline models.
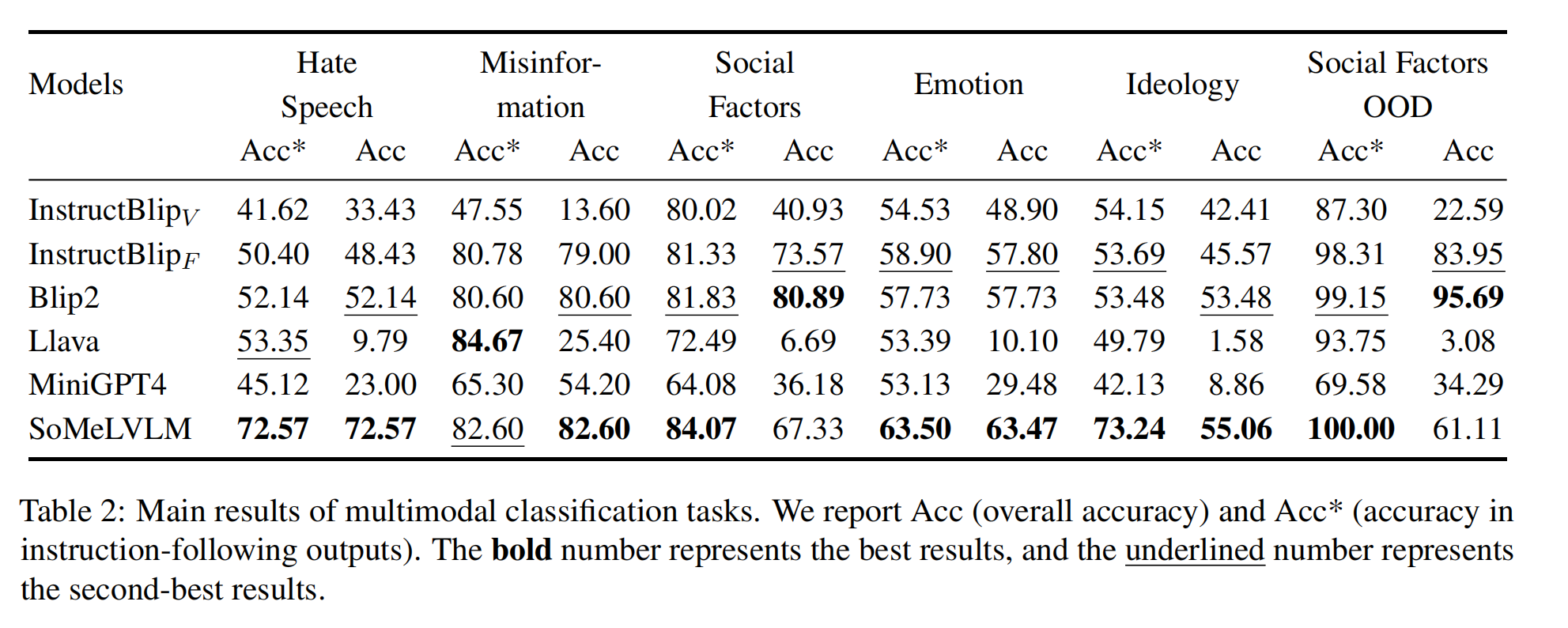
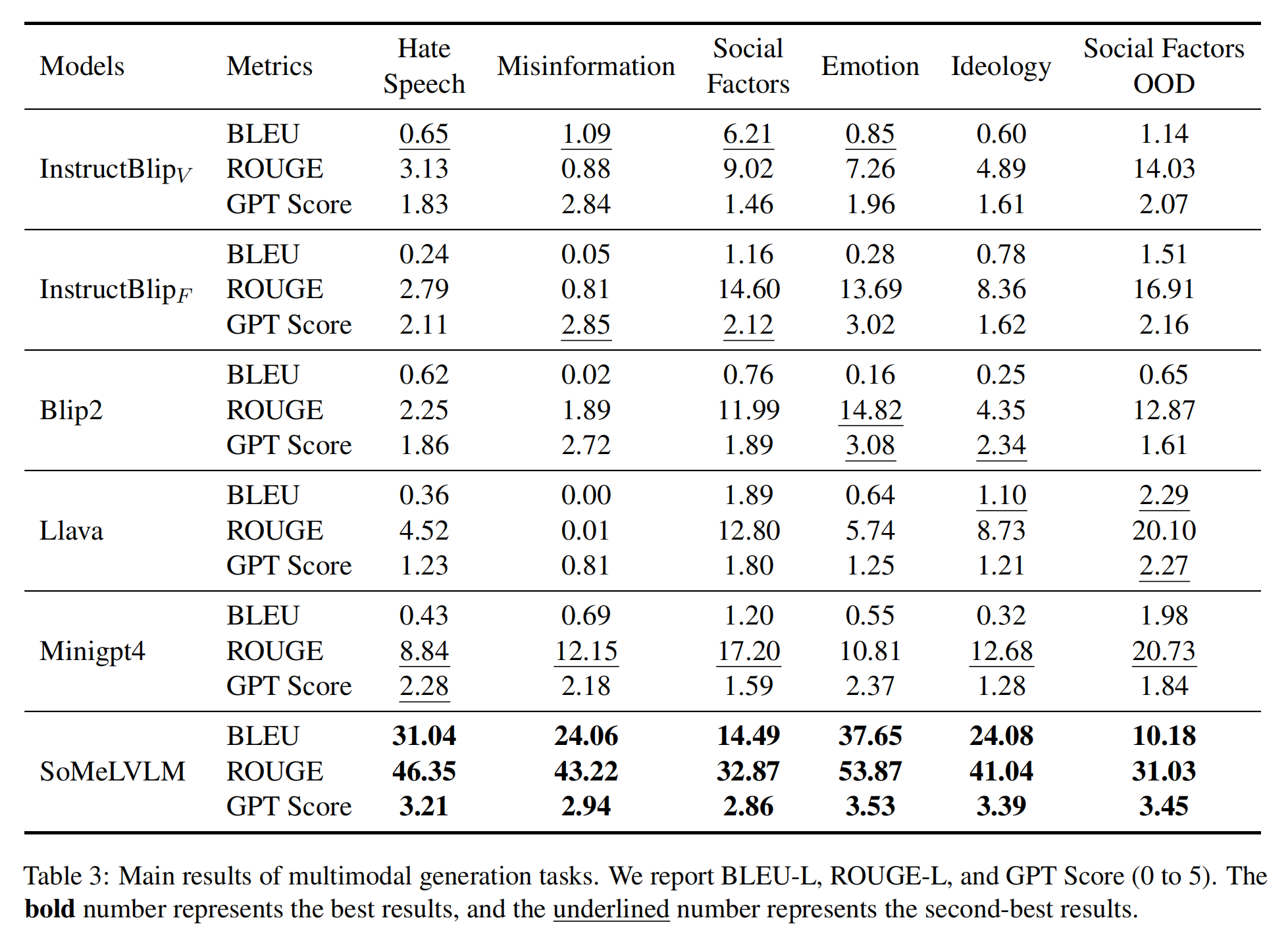
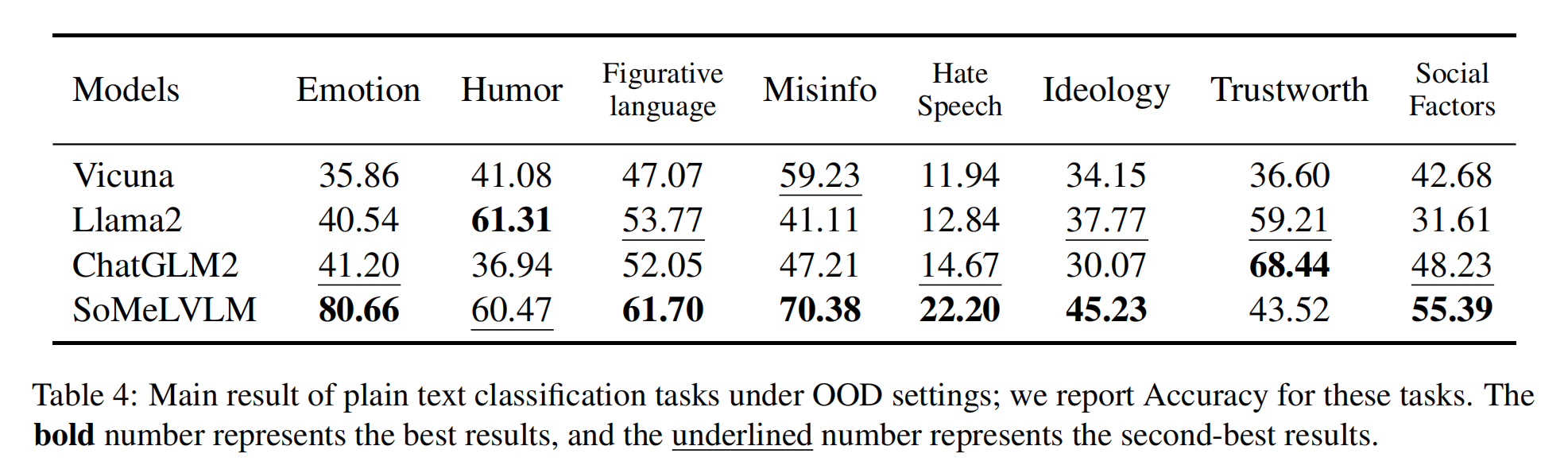
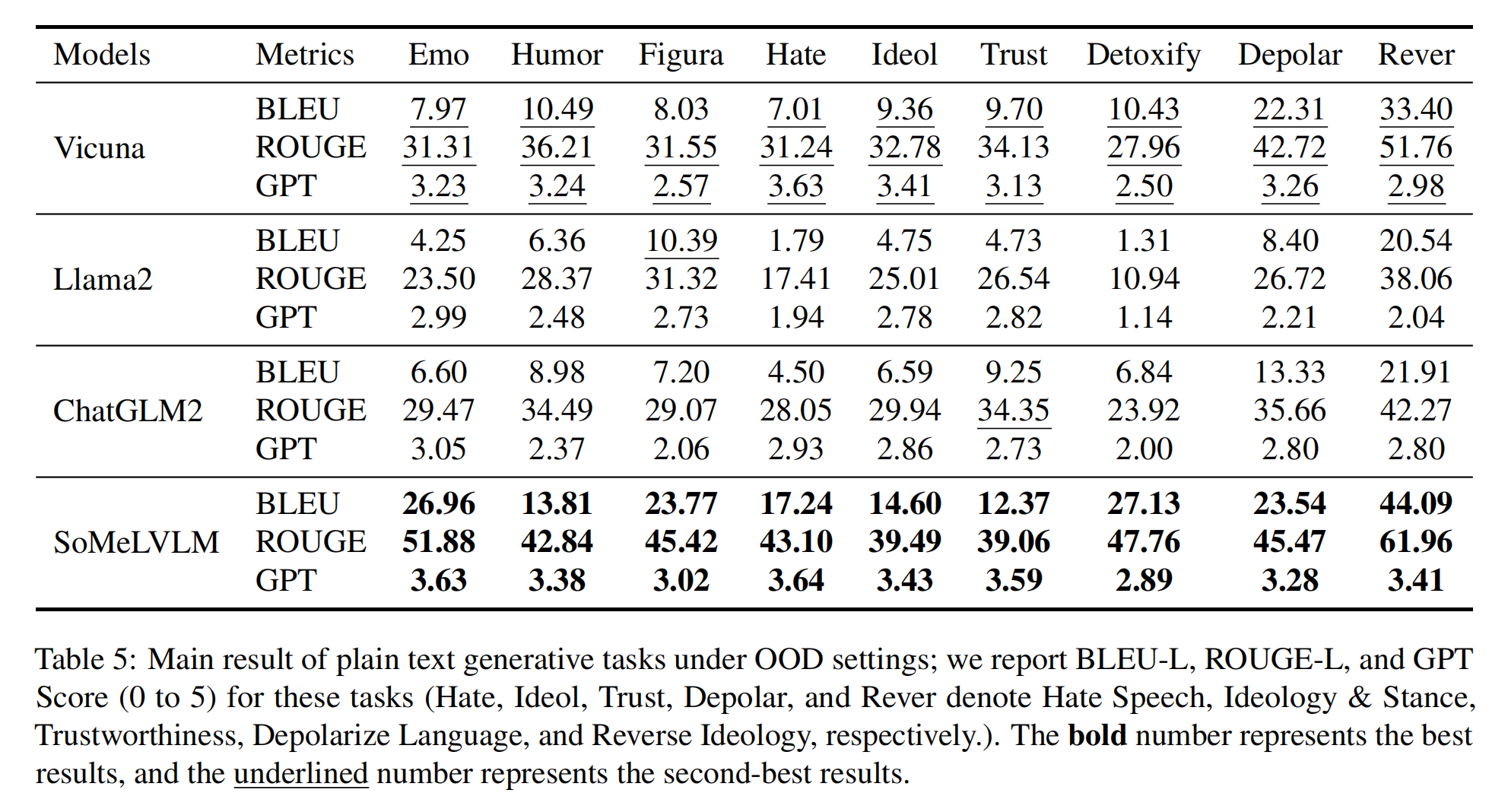
Cognitive Abilities Analysis: We collect results according to the cognitive abilities mentioned in our framework. Specifically, we collect the in-domain performance of multimodal parts (using overall Acc performance) and the OOD performance of plain-text parts at the dataset level and categorize them into Knowledge & Comprehension, Application, Analysis, Evaluation, and Creation, five cognitive levels in total.
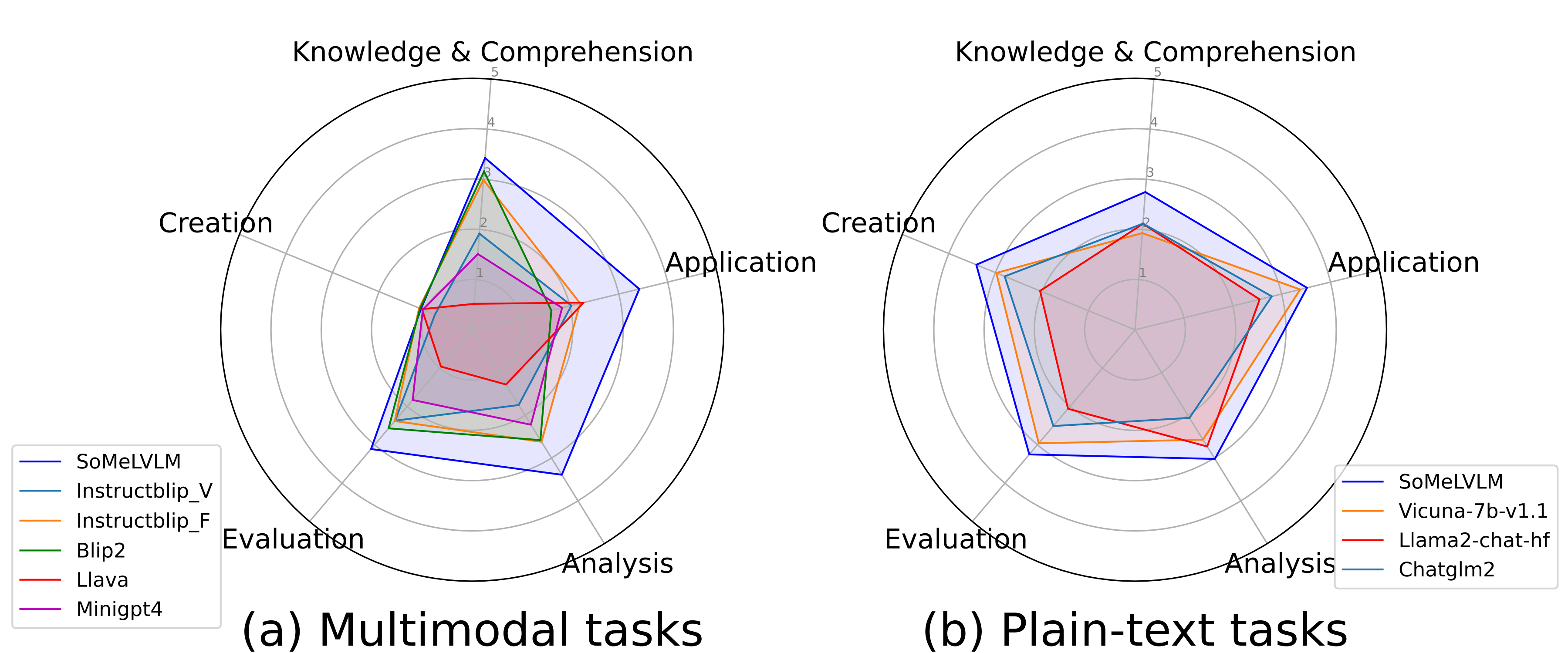
Clearly, SoMeLVLM shows greater cognitive ability over baseline models in all of the cognitive levels. At the multimodal Creation level, all of the models perform poorly as they are required to generate three hashtags that best describe the post, which is not an easy task even for human beings.
Demo
Conclusion
In our work, we introduce SoMeLVLM, a multimodal language model for social media processing, wherein we design five cognitive capabilities, each of which is mapped to various levels of social media tasks.
Building on this, we collect related plain text and multimodal datasets and enhance the capabilities of vision-language models on relevant tasks through instruction tuning. Additionally, we construct an evaluation based on cognitive levels and test our model under zero-shot conditions, comparing it with other advanced LLMs and LVLMs. The experimental results thoroughly demonstrate the superiority of our model. Our work contributes to the computational social science field by providing methods for modeling and evaluating various tasks on social media and a large-scale, high-quality multimodal social media dataset.
Related Works about Social Media
- Hanjia Lyu, Jinfa Huang, Daoan Zhang, Yongsheng Yu, Xinyi Mou, Jinsheng Pan, Zhengyuan Yang, Zhongyu Wei, Jiebo Luo.
Unveiling the Truth and Facilitating Change: Towards Agent-based Large-scale Social Movement Simulation
- Xinyi Mou, Zhongyu Wei, Xuanjing Huang.
PASUM: A Pre-training Architecture for Social Media User Modeling based on Text Graph
- Kun Wu*, Xinyi Mou*, Lanqing Xue, Zhenzhe Ying, Weiqiang Wang, Qi Zhang, Xuanjing Huang, Zhongyu Wei.
Unifying Local and Global Knowledge: Empowering Large Language Models as Political Experts with Knowledge Graphs
- Xinyi Mou, Zejun Li, Hanjia Lyu, Jiebo Luo, Zhongyu Wei.
Align Voting Behavior with Public Statements for Legislator Representation Learning
- Xinyi Mou, Zhongyu Wei, Lei Chen, Shangyi Ning, Yancheng He, Changjian Jiang, Xuanjing Huang.